책에 비유하자면
- 클러스터링 인덱스는 페이지를 이미 알기 때문에 바로 그 페이지를 펴는 것
- 세컨더리 인덱스는 목차에서 찾고자 하는 내용의 페이지를 찾고 그 페이지로 이동하는 것
- 테이블 스캔은 처음부터 한 장씩 넘기면서 내용을 찾는 것이다.
1. 클러스터링 인덱스
클러스터링이란 여러 개를 하나로 묶는다는 의미로 주로 사용된다. MySQL에서 클러스터링 인덱스는 InnoDB 스토리지 엔진에서만 지원하며 PRIMARY KEY(이하 PK)를 기준으로 여러 레코드를 묶어서 저장하는 형태로 구현된다. 이는 비슷한 값들을 동시에 조회하는 경우가 많다는 점에서 착안한 것이다. 여기서 중요한 점은 PK 값에 의해 레코드의 물리적인 저장 위치가 결정된다는 것이다. 또한 PK 값이 변경된다면 그 레코드의 물리적인 저장 위치가 바뀌어야 한다는 것을 의미하기도 한다.
클러스터링 인덱스는 PK 값에 의해 레코드의 저장 위치가 결정되므로 사실 인덱스 알고리즘이라기보다 테이블 레코드의 저장 방식이라고 볼 수 있다. (클러스터링 인덱스 == 클러스터링 테이블) InnoDB와 같이 항상 클러스터링 인덱스로 저장되는 테이블은 PK 기반의 검색이 매우 빠르지만 상대적으로 레코드의 저장이나 PK값 변경이 느리다.

그림 (1)를 보면 구조 자체는 B-Tree와 비슷하게 보인다. 하지만 B-Tree의 리프 노드는 세컨더리 인덱스(보조 인덱스, 정렬 컬럼, PK값) 정보가 저장되어 있지만 클러스터링 인덱스 리프 노드에는 레코드의 모든 칼럼이 같이 저장돼 있음을 알 수 있다.
UPDATE tb_test
SET emp_no = 100002
WHERE emp_no = 100007;그림 (1) 클러스터링 테이블에서 위 쿼리와 같이 PK를 변경하는 문장을 실행하면 아래 그림(2)가 된다.

emp_no가 100007인 레코드는 3번 페이지에 저장되어 있었는데 emp_no가 1000002로 변경되면서 2번 페이지로 이동한 것을 알 수 있다. PK값은 원칙적으로 변경되지 않아야 한다.
2. 세컨더리 인덱스에 미치는 영향
클러스터링 인덱스(PK)를 제외한 인덱스를 말한다. MyISAM이나 MEMORY 테이블은 INSERT 될 때 처음 저장된 공간에서 절대 이동하지 않는다. 데이터 레코드가 저장된 주소는 내부적인 레코드 아이디(ROWID) 역할을 한다. 하지만 InnoDB 테이블에서 세컨더리 인덱스는 레코드의 주소값을 저장하지 않고 PK값을 저장하도록 구현돼 있다.
SELECT *
FROM employees
WHERE first_name = 'Aamer';만약 employees 테이블에 emp_no 컬럼의 PRIMARY KEY 클러스터링 인덱스와 ix_firstname ( first_name ) 세컨더리 인덱스가 있는 상황에서 위 쿼리가 실행되었을 MyISAM 테이블과 InnoDB 테이블의 인덱스 처리 방식을 살펴보자.
- MyISAM: ix_firstname 인덱스를 검색해서 레코드의 주소를 이용해 최종 레코드 리턴
- ① InnoDB: ix_firstname 인덱스를 검색해 레코드의 PK 값을 확인 후, 클러스터링 인덱스를 검색해서 최종 레코드 리턴
MyISAM는 한 번 처리로 레코드를 리턴하지만 InnoDB는 두 번의 처리가 필요하다.
3. 클러스터링 인덱스 장점과 단점
3.1 장점
- PK로 검색할 때 처리 성능이 매우 빠름 (특히 PK 범위 검색하는 경우)
- 테이블의 모든 세컨더리 인덱스가 PK값을 가지고 있기 때문에 PK값을 가져오는 경우에는 인덱스로 처리될 수 있는 경우가 많고 이를 커버링 인덱스라고 한다.
3.2 단점
- 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 갖기 때문에 클러스터링 키 값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐
- 세컨더리 인덱스를 통해 검색할 때 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능이 느림 ( ①과 관련 )
- INSERT 할 때 PK에 의해 레코드의 저장 위치가 결정되기 때문에 처리 성능이 느림
- PK를 변경할 때 레코드를 DELETE하고 INSERT하는 작업이 필요하기 때문에 처리 성능이 느림
4. 클러스터링 테이블 사용 시 주의사항
4.1 클러스터링 인덱스 키의 크기
클러스터링 테이블의 경우 모든 세컨더리 인덱스가 PK 값을 포함한다. 그래서 PK의 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커진다. 일반적으로 세컨더리 인덱스가 더 많이 생성된다는 것을 고려하면 세컨더리 인덱스 크기는 급격히 증가한다. 5개의 세컨더리 인덱스를 가지는 테이블의 PK가 10 byte인 경우와 50 byte인 경우를 한번 비교해 보자
| PK 크기 | 레코드당 증가하는 인덱스 크기 | 100만 건 레코드 저장 시 증가하는 인덱스 크기 |
| 10 byte | 10 byte * 5 = 50 byte | 50 byte * 1,000,000 = 47MB |
| 50 byte | 50 byte * 5 = 250 byte | 250 byte * 1,000,000 = 238MB |
인덱스 크기가 커질수록 같은 성능을 내기 위해 그만큼의 메모리가 더 필요해지므로 InnoDB 테이블의 PK는 신중히 선택해야 한다.
4.2 PK 선택
클러스터링 테이블에서 PK는 그 의미만큼이나 중요한 역할을 하기 때문에 대부분 검색에서 상당히 빈번하게 사용되는 것이 일반적이다. 그러므로 설령 그 컬럼의 크기가 크더라도 업무적으로 해당 레코드를 대표할 수 있다면 그 컬럼을 PK로 설정하는 것이 좋다.
여러 개의 컬럼이 복합으로 PK가 만들어지는 경우 PK의 크기가 길어질 떄가 있다. 하지만 PK크기가 길어도 세컨더리 인덱스가 필요치 않다면 그대로 PK로 사용하는 것이 좋다. 하지만 세컨더리 인덱스도 필요하고 PK의 크기도 길다면 AUTO INCREMENT 인조식별자를 추가한다. 로그 테이블과 같이 조회보다는 INSERT 위주의 테이블들은 AUTO INCREMENT 인조식별자를 사용하는 것이 성능 향상에 도움이 된다.
5. 대리키와 복합키 비교
5.1 비식별관계

Post 테이블의 id와 Comment 테이블의 comment_id 컬럼 모두 AUTO INCREMENT 대리키를 사용하였다. Comment 테이블에서 post_id 컬럼을 FK로 설정해 Post 테이블과 연관관계를 맺었다.

그림 (4)에서 Post 테이블의 PK와 Comment 테이블의 post_id 컬럼으로 조인이 된다. Comment 테이블에는 post_id가 FK이기 때문에 세컨더리 인덱스가 생성되어 있기 때문에 Index Range Scan을 통해 서로 맵핑된다.
SELECT 결과를 가져오기 위해 Comment 테이블의 레코드를 검색하게 되고 이 과정에서 랜덤 I/O가 발생하게 된다. comment_id 컬럼의 100, 200 값은 다른 페이지에 저장되어 있기 때문에 두 번의 페이지 읽기 작업이 필요하게 된다.
5.2 식별 관계
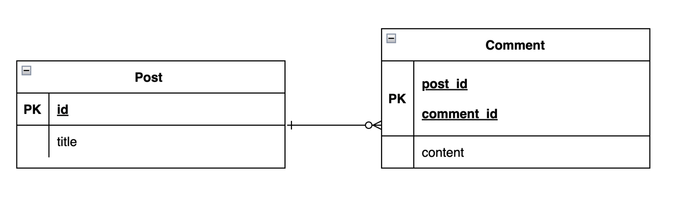
Post 테이블의 id는 AUTO INCREMENT 대리키를 사용하였다. Comment 테이블은 post_id 컬럼을 FK로 설정하여 Post 테이블과 연관관계를 맺었으며 post_,id, comment_id 컬럼을 조합해 복합키로 PK를 설정하였다. comment_id는 시퀀스 성격의 순번 컬럼이다

그림 (6)에서 Post 테이블의 PK와 Comment 테이블의 post_id 컬럼으로 조인이 된다. Comment 테이블에는 post_id가 PK이기 때문에 클러스터링 인덱스이며 comment_id값이 연속되어 있기 때문에 post_id값이 다른 값이 나올 때까지 스캔만 하면 되기 때문에 효율적으로 레코드를 읽어오게 된다.
참고자료
'SQL > MySQL' 카테고리의 다른 글
| 정렬 ORDER BY (0) | 2025.03.12 |
|---|---|
| 옵티마이저 Optimizer (0) | 2025.03.06 |
| 인덱스 Index - (5) (0) | 2025.03.05 |
| 인덱스 Index - (4) :B-Tree 인덱스를 통한 데이터 읽기 (0) | 2025.03.05 |
| 인덱스 Index - (3) (0) | 2025.03.05 |


